2025
Co-author
Research Project
Xuting Liu, Daniel Alexander, Behnaz Arzani, Siva Kesava Reddy Kakarla, Vincent Liu
Python, PyTorch, CUDA, Sarathi Framework
In submission to NSDI'26
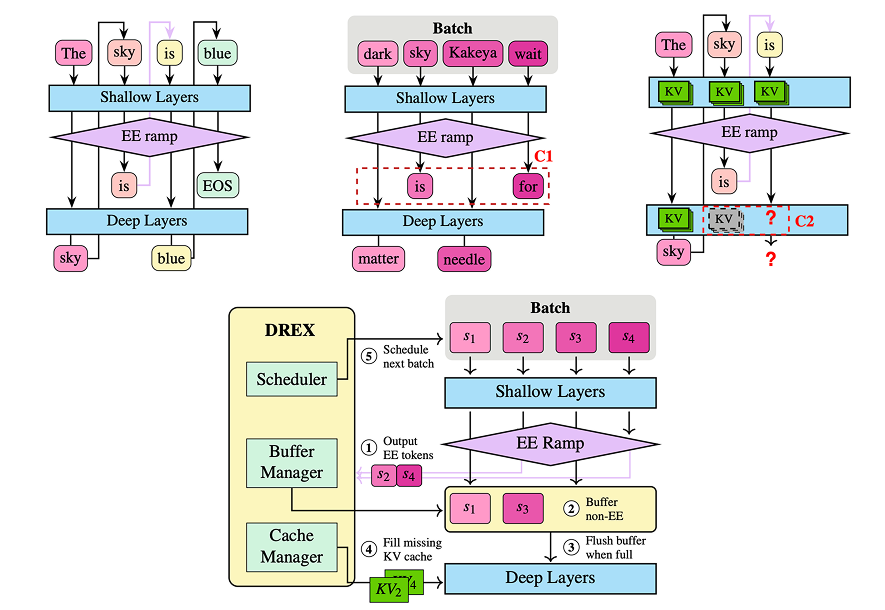
DREX — Dynamic Rebatching for Early-Exit LLM Inference
Xuting Liu, Daniel Alexander, Behnaz Arzani, Siva Kesava Reddy Kakarla, Vincent Liu (In submission to NSDI'26)
Background: Early-Exiting (EE) in Large Language Models (LLMs) is a technique that aim to accelerate inference by allowing "easy" tokens to exit the model early to save computational resources. However, operationalizing EE LLMs remains a challenge, since EE has mostly been studied in a single-inference setting. This project aims to extend EE LLM serving in a batched setting by introducing DREX, the first system that operationalizes EE LLMs through Dynamic Rebatching. DREX integrates two major innovations: a copy-free rebatching mechanism that eliminates physical data movement, and a memory-efficient state-copying approach that reduces redundant KV cache usage. Together, these optimizations deliver up to 2–12× throughput improvements over baseline frameworks while maintaining high output quality and eliminating involuntary exits.
Key Responsibilities:
- Algorithm design: designed the dynamic rebatching algorithm on the Sarathi serving framework, implemented an efficient batch-wise KV cache copying mechanism, implemented BERT score as a metric of output quality.
- Experiment running: extended the experimental suite to NVIDIA A100, H200, RTX 3090Ti, and RTX 5090Ti GPUs running Llama 2-7b,13b,70, and Qwen-14b models, introduced new workloads and datasets including HumanEval for code generation and XSUM for abstract summarization.
- Technical Writing: Contributed to the paper's techincal writing, generated key experimental figures in PGFPlots: throughput vs. confidence scores, early-exit proportion breakdowns, and memory efficiency visualization, and adapted design figures to TikZ.